Grep is a vital command in Linux and Unix systems used predominately for searching text and strings within files. Essentially, the grep command scans the specified file for lines that contain the specified strings or words. This command can come in handy or prove useful for developers and system administrators on Linux and Unix-like systems.
Grep, is an acronym for “Global Regular Expression Print”. In this post I will demonstrate how to use the grep command with practical examples. So let’s go and explore how to use grep.
Origin
The name ‘grep'originated from the command used to perform a similar command with a text editor called ed used in the Linux/Unix platforms.
Grep utilities are a family that includes: grep -E (formally egrep) and grep-F (formally – you guessed it – fgrep). these were used for searching files. fgrep was significantly preferred due to its speed and its search scope i.e words and strings. Typing grep is easy hence it’s been a preferred choice.
Basic Syntax
To search for a string in a file, we run the command in this format:
$ grep "string" file name
1. How to use grep to search a file on Linux
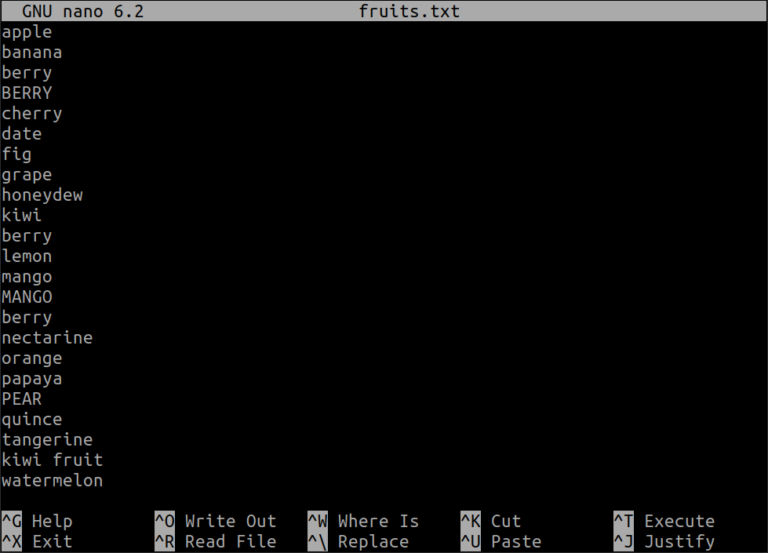
I will create a sample file with the nano command on a Linux machine to illustrate how to use the “grep” command. Let’s call this file fruits.txt
Lets go through some grep commands using this file:
1.1. Basic Search
Lets find the line containing the word “apple”
1.2. Case-Insensitive search
To search for “mango” regardless of case
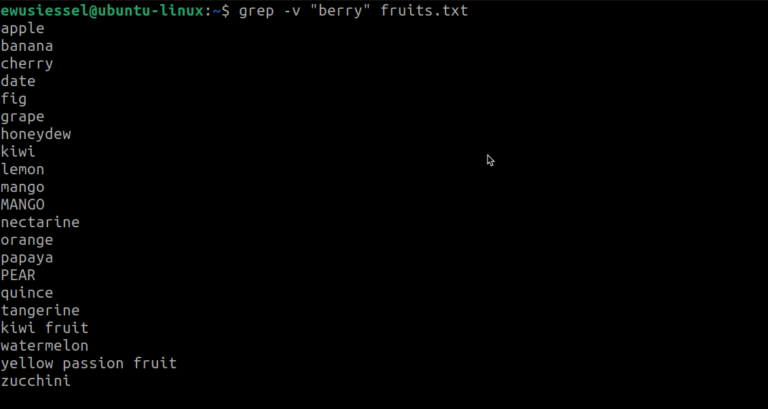
1.3. Search for lines that do not match a pattern
To find lines that do not contain the word “berry”
1.4. Count Matching Lines
To count how many lines contain the word “berry”
1.5. Display line numbers with matching lines
To display numbers of lines displaying the word “fruit”
1.6. Search for multiple patterns
To search for lines containing “apple” or “mango”
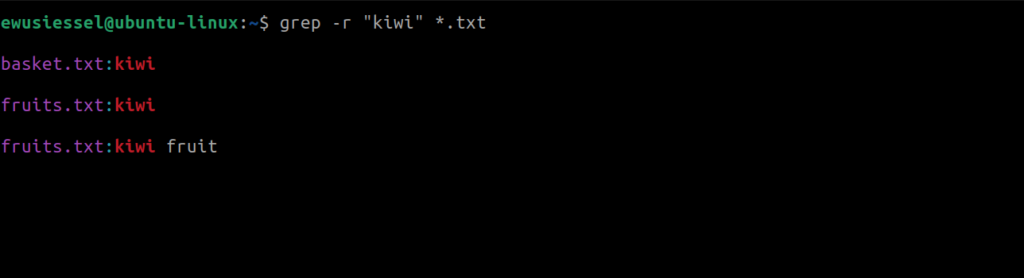
1.7. Recursive search in directories
Lets assume you have multiple .txt files in a directory, to search for “kiwi” in all .txt files in the current directory, for this demonstration I created an additional file named basket.txt with a few items similar to those in the fruits.txt file. Now let’s search for ‘banana’ in all the files within the current directory.
2. Practical Search Log Files
Now lets put on our cybersecurity professional hat and explore some practical examples of using `grep` command. Lets search a log file in our Linux virtual box, I deliberately attempted to log into my Ubuntu machine with false credentials on purpose so I could demonstrate this example:
Pro Tip: I can decide to use:
grep -c “authentication failure” /var/log/auth.log to find and display the number of failed login attempts.
2.1 Analysing Configuration Files
Lets check for specific configurations in sshd_config:
2.2 Using Extended Regular Expression
Finding lines with either “error” or “warning” (case insensitive) in the Linux syslog:
2.3 Combining grep with Linux Commands
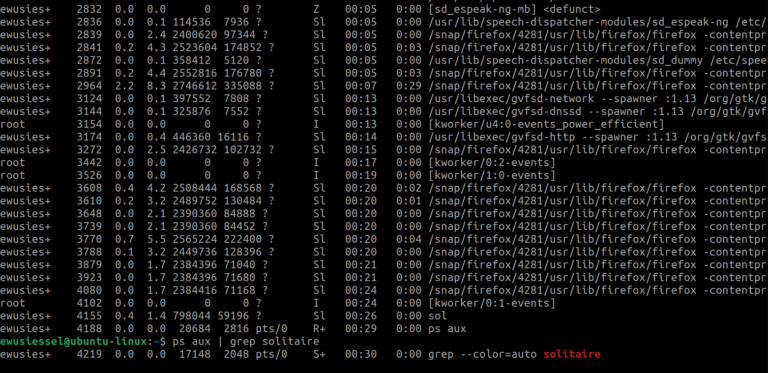
The ps aux command is frequently used in Linux to retrieve details about running processes. For example, I was previously playing Solitaire, we can use grep to find this specific process.
Tip: the kill -9 command followed by the process ID will terminate that specific process.
Advanced Linux Commands with grep
It took me some time to understand this, but I will demonstrate and explain how to use Linux commands such as awk, cut, sed, with grep and how they can be useful for “harvesting” system information.
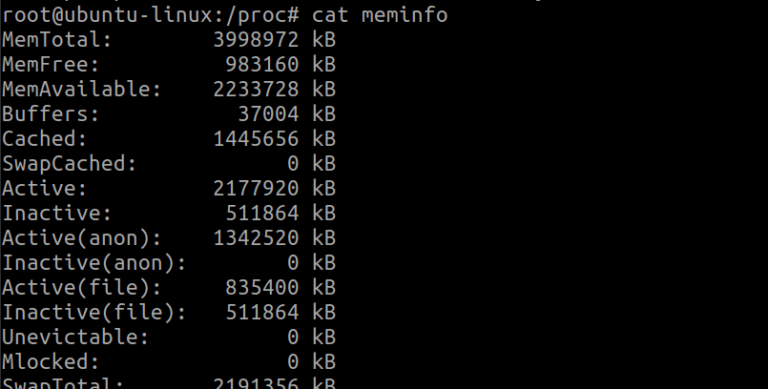
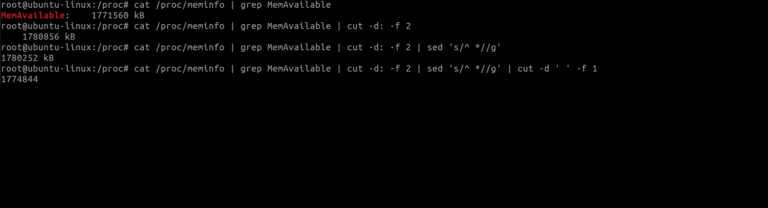
Let’s switch to the root user for the tasks we are about to perform. I will attempt to harvest data from my total usable memory. This information can be found in /proc/meminfo
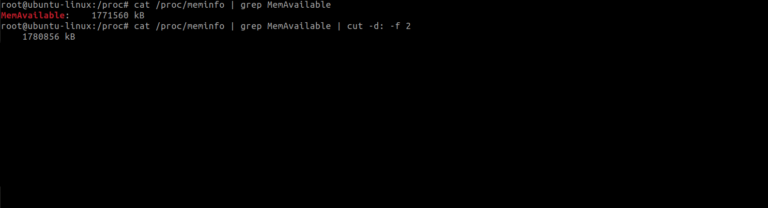
Lets use the grep command to display only the available memory i.e. MemAvailable
Based on the output, our goal is to split the text by isolating the number. To achieve this, we use the cut command with the following format:
-d: This option specifies the delimiter, a special character or sequence of characters that marks the boundaries between different components, fields, or elements within a text file or data stream. In this case, the delimiter is a colon (:).
-f: This option specifies the field, we use -f 2, which indicates that we want to extract the second field.
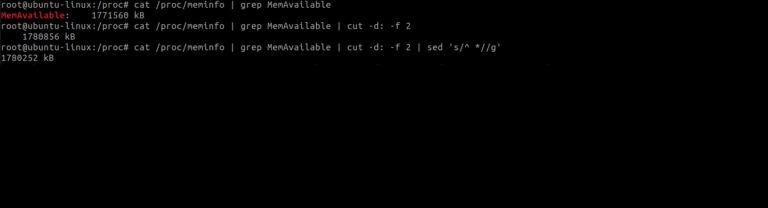
I have removed the first characters from our previous output, but there is still a leading space in the result. To eliminate this leading space, we use the following approach with the sed command:
The caret ^ is used to indicate the beginning of the line.
A space * denotes any character(s) following it.
The // pattern is used to specify that we want to remove the leading space completely.
The g at the end indicates closure.
This way the leading space is entirely removed from the output.
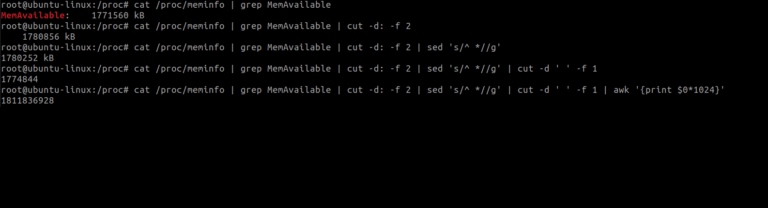
Our next task is to remove kilobytes – “kB” from the output. Once again will use the cut command with the
-d specifies the delimiter, which in this case is the space between the number and “kB” (denoted by ' ').
-f 1 specifies the field. We want to keep the first field, which is the number.
Now that we have just the number let us multiply it by 1024 to convert it to bytes with the awk command
$0 denotes the first argument or the entire input line.
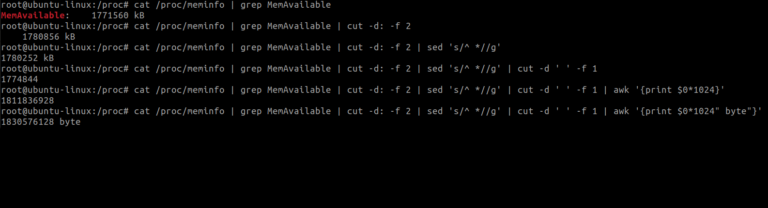
We can go further by concatenating a string to our final output.
Conclusion
The ‘grep’ command is an invaluable tool in the Linux command-line arsenal, providing powerful capabilities for searching and filtering text within files. We’ve covered the basic syntax of ‘grep’, illustrated with examples using a sample file, and demonstrated how to combine ‘grep’ with other advanced Linux commands to efficiently search through log files. Whether you are a security analyst, system administrator, or developer, mastering grep can significantly enhance our ability to quickly and effectively locate the information we need within large volumes of data.